 Paper (arXiv)
Paper (arXiv)
 Supplemental Results
Supplemental Results
 Teaser Video
Teaser Video
 Code
Code
Dynamic 6-DoF rendering of scenes from Google Immersive, Technicolor, and Neural 3D Video datasets.
Static 6-DoF rendering of highly view-dependent scenes from Shiny and Stanford datasets.
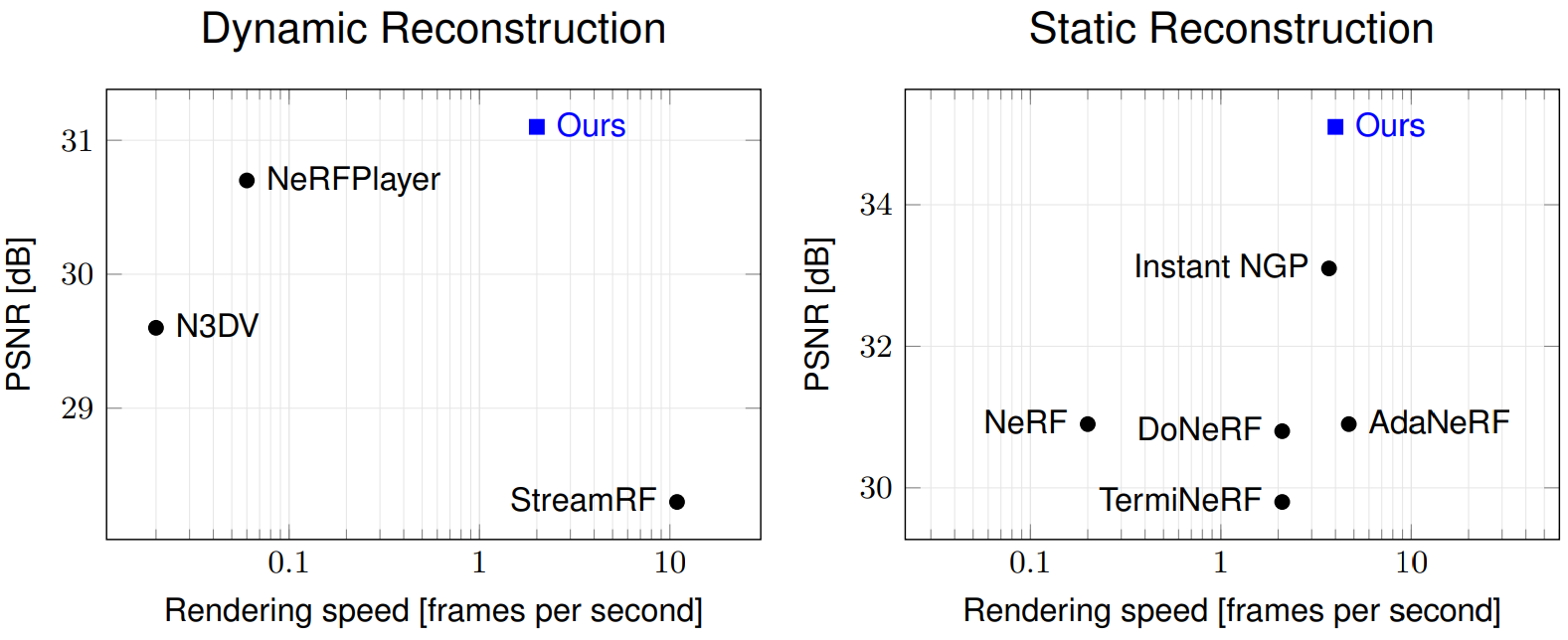
Speed-quality trade-off of our method compared to the state of the art.
Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel — a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory-efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code.
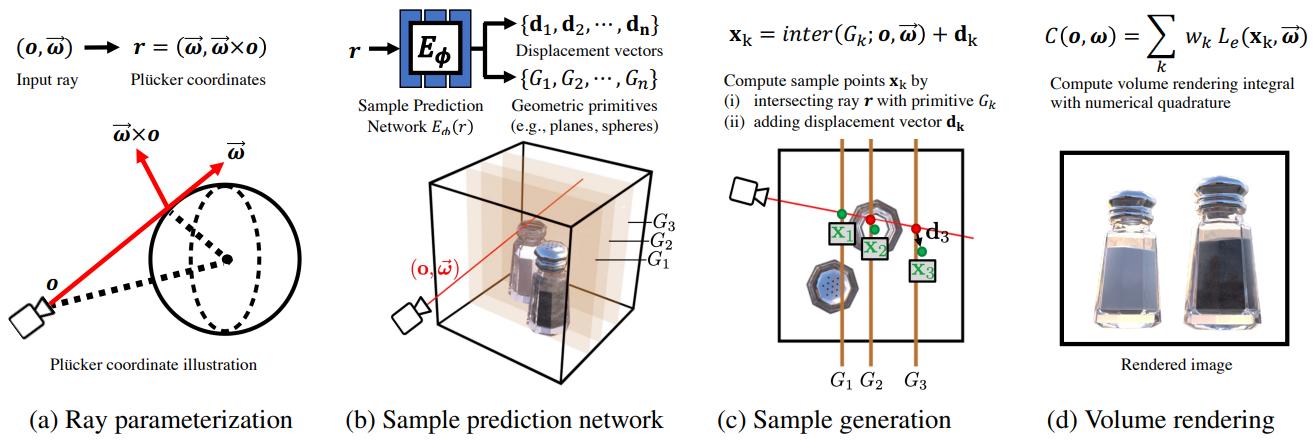
Our sample prediction network, illustrated below, is unique compared to other approaches in that it
both accelerates volume rendering and improves rendering quality,
especially for challenging view dependent scenes.
The keyframe-based volume representation that we employ is an extension of TensoRF [Chen et al. 2022].
It compactly represents a full video sequence, consuming roughly the same amount of memory as a TensoRF for a single static frame.
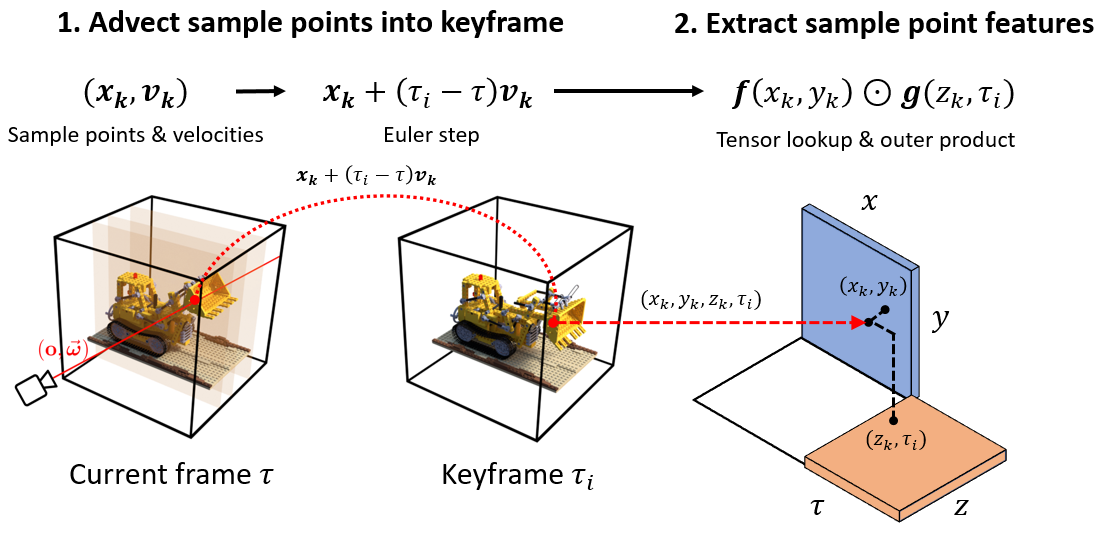
The combination of our sample prediction network and keyframe-based volume representation comprise HyperReel, which achieves a balance between high rendering quality, speed, and memory efficiency
that sets it apart from existing 6-DoF video representations.
We show real-time demos of our approach at 512x512 pixel resolution applied to both dynamic and highly-view-dependent static scenes below. You can run our method and these real-time demos using our codebase.
@inproceedings{attal2023hyperreel,
title = {{HyperReel}: High-Fidelity {6-DoF} Video with Ray-Conditioned Sampling},
author = {Attal, Benjamin and Huang, Jia-Bin and Richardt, Christian and Zollhoefer, Michael and Kopf, Johannes and O'Toole, Matthew and Kim, Changil},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
arxiv = {2301.02238},
}We thank Thomas Neff, Yu-Lun Liu, and Xiaoming Zhao for valuable feedback and discussions, Zhaoyang Lv for help running the Neural 3D Video Synthesis codebase, and Liangchen Song for providing information about the scenes from the Google Immersive Video dataset used in NeRFPlayer. Matthew O'Toole acknowledges support from NSF IIS-2008464.